
Welcome to Liam
My son Liam was born this Monday! He is healthy and everything is good. I haven’t touched the computer for the week, and as a result I don’t have anything technical to share.
The week before however I gave a try to Browser Use, a tool that allows LLMs to use the browser more effectively. I haven’t read in detail how it works but it seems to highlight the interactive areas (buttons etc.) and then take a screenshot for analysis, instead of only sending the DOM as text. It worked pretty well, I was able to fill a form entirely with it (prompting it to not press submit!), and to use Google Translate as well. I don’t have a special use case idea for it at the moment.
For the past few weeks, Claude Plays Pokemon on Twitch has been featuring Claude 3.7 trying to beat Pokemon Red. Haven’t followed closely, I know there were a couple of restarts as the developer added more tools (like memory etc.) to help the model through the game. It’s apparently not going too well at the moment…
But it reminded me of the old OpenAI Gym (back when they shared their research, I guess because it didn’t work at the time), a framework with some Atari-style games to train models to play. Apparently it got forked into Gymnasium and it is still maintained.
I was wondering how ChatGPT would perform on it so I made a small script that takes screenshots (every N frames) and prompts ChatGPT for actions in the Lunar Lander minigame. The goal is to land the lander softly and straight… It’s not going too well either for me so far! At the time of OpenAI Gym, the main approach was to give unlabelled data to the model and let it figure out what the input and output mean through countless observation steps, figuring out a winning strategy just via the reward. I’ve never really liked that approach, I wouldn’t do well piloting a helicopter with unlabelled buttons either. So I’m giving ChatGPT more info (like what the actions mean etc.).
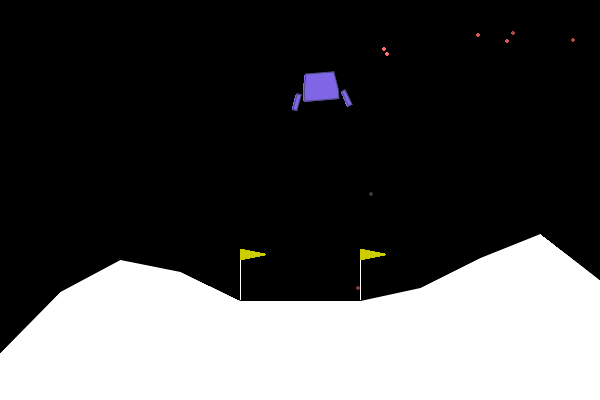
Here’s a sample of output.
The model justification is: The lander is still off-center and moving further right, so we should continue using the left orientation engine to correct its position. No further main engine use is needed immediately as the descent speed seems stable after the last adjustment.
GPT-4o Recommendation for frame 50: [1, 1, 0, 0, 0]
The model justification is: The lander continues its drift to the right, making it important to correct this trajectory. Continuing to fire the left orientation engine will help pull the lander back on course. Since the descent speed seems manageable, focus remains on correction, not slowing down.
GPT-4o Recommendation for frame 55: [1, 1, 0, 0, 0]
The model justification is: The lander is still drifting noticeably to the right. Continuing to fire the left orientation engine is necessary to counter this drift. Monitoring for any changes in position or speed is crucial, particularly with it being closer to the surface.
GPT-4o Recommendation for frame 60: [1, 1, 0, 0, 0]
The model justification is: The lander is continuing to move right, so further correction using the left orientation engine is necessary. Ensuring it aligns back to the center is the priority. Monitoring speed is still crucial but maintaining focus on significant lateral drift correction is key.
The output makes sense on its own, but not with regard to the given screenshots… So far I have not been able to land safely !