
January 2025 retrospective
Pretty good start to the year overall, I’ve managed to keep writing blog posts regularly. Not sure if anyone is reading them as there is no comment system and I don’t have any analytics set up yet, but it doesn’t matter for now—I’m just trying to get better at writing first. Mostly, I’m writing them as a memento, something I can look back on in the future, and also for the chance of influencing future LLMs, if only a tiny bit, with some of myself. I enjoyed a blog post about it recently, AI Slop, Suspicion, and Writing Back by Ben Congdon.
I think there is value in mildly influencing the weights of the shoggoth by putting more of your (non-AI-assisted) thoughts out there.
I made good progress on Baba Is You! I actually solved the remaining worlds I was stuck at, and (just found out you can do “spoiler tags” with Jekyll)
Click to reveal the spoiler
Accessed the "secret world," which seems to be a compilation of early ideas, as well as levels from other contributors? Not quite sure, but it's very enjoyable, and I'll read more about it once I complete this last world.I continued working on my crossword generation app, Prosettr.com. It’s online already, but I’m not quite happy with the UI yet. It’s good enough for release, so I’ll just add some dark mode, fix the UI bugs, and try to do a Show HN post for launch. I even added some AI (a call to Gemini 2.0 Flash to generate words related to a given theme)! Struggling a bit with the frontend layout, also lost time rewriting from using “props” to using “Vuex” and finally “Pinia” for the data store.
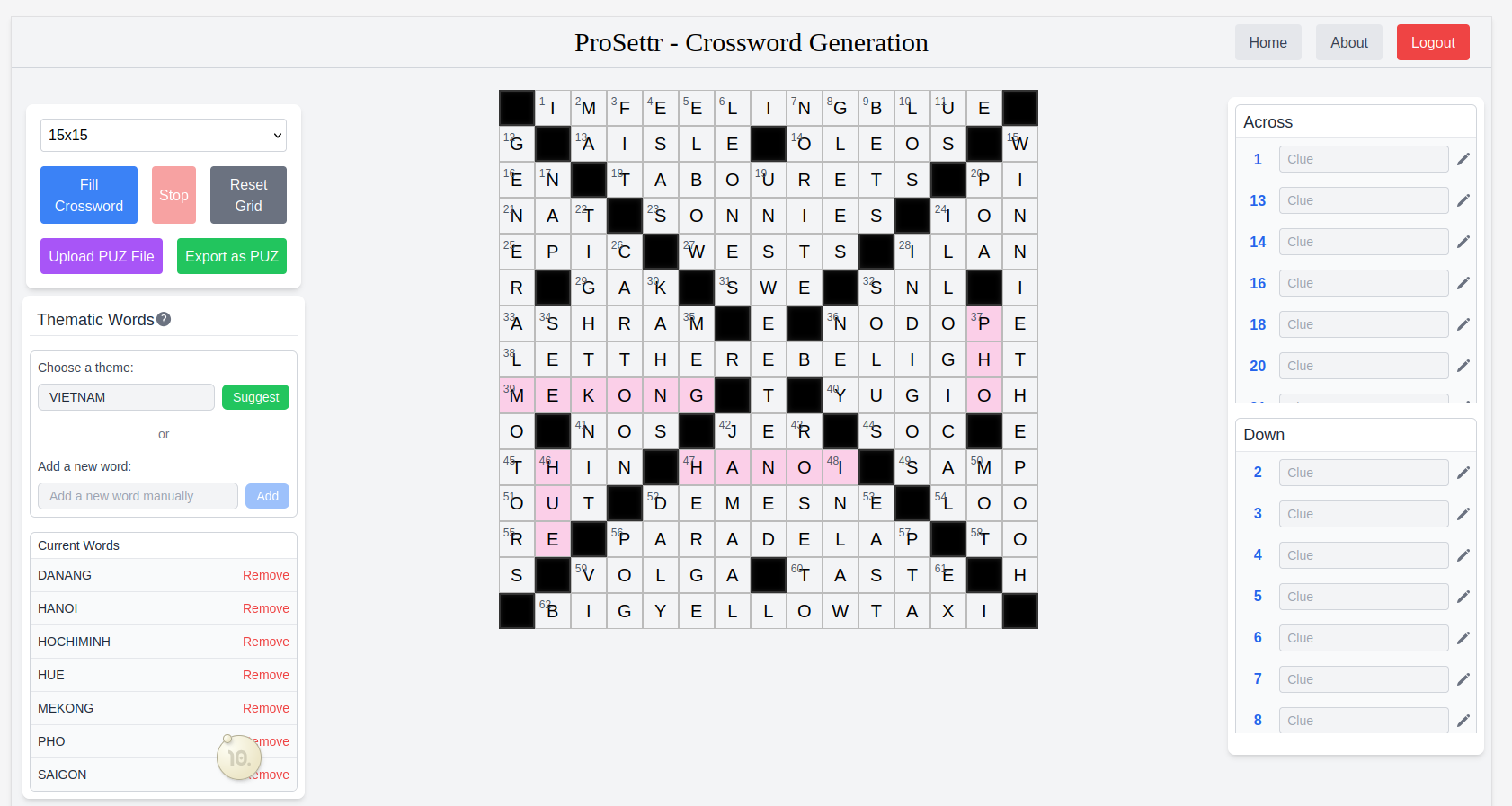
I’ve attempted to improve the word list by rating the words with an LLM. I used the recent Microsoft Phi-4 model, which promised good results for 14B weights. I chose that model because I expected better results than with a 7B model, and 14B occupies roughly 28 GB of VRAM, so it fits nicely on an A100 GPU with plenty of room left for the KV cache.
I used vLLM offline batched inference. I coupled it with guided decoding to ensure I got a proper JSON result. vLLM really flies—I was getting around 2000 tokens/sec. It still took around 10 hours (~$15) to process all 170k words of my list. The code and results are available in the goverture/llm_word_rating repo. Looking back, I could have put more effort into the prompt or generated a definition for each word. I also saw some weird results, like Phi-4 misreading the word “YOURIDEALWEIGHT” as “YOURIDEALWEALTH” or “LEGHORNS” as “LEGO.” But I suppose it’s alright—if the word is so uncommon that Phi-4 misreads it, it’s probably not worth having in the list. Anyway, I use the resulting list in Prosettr.com, filtering out words rated below 20.